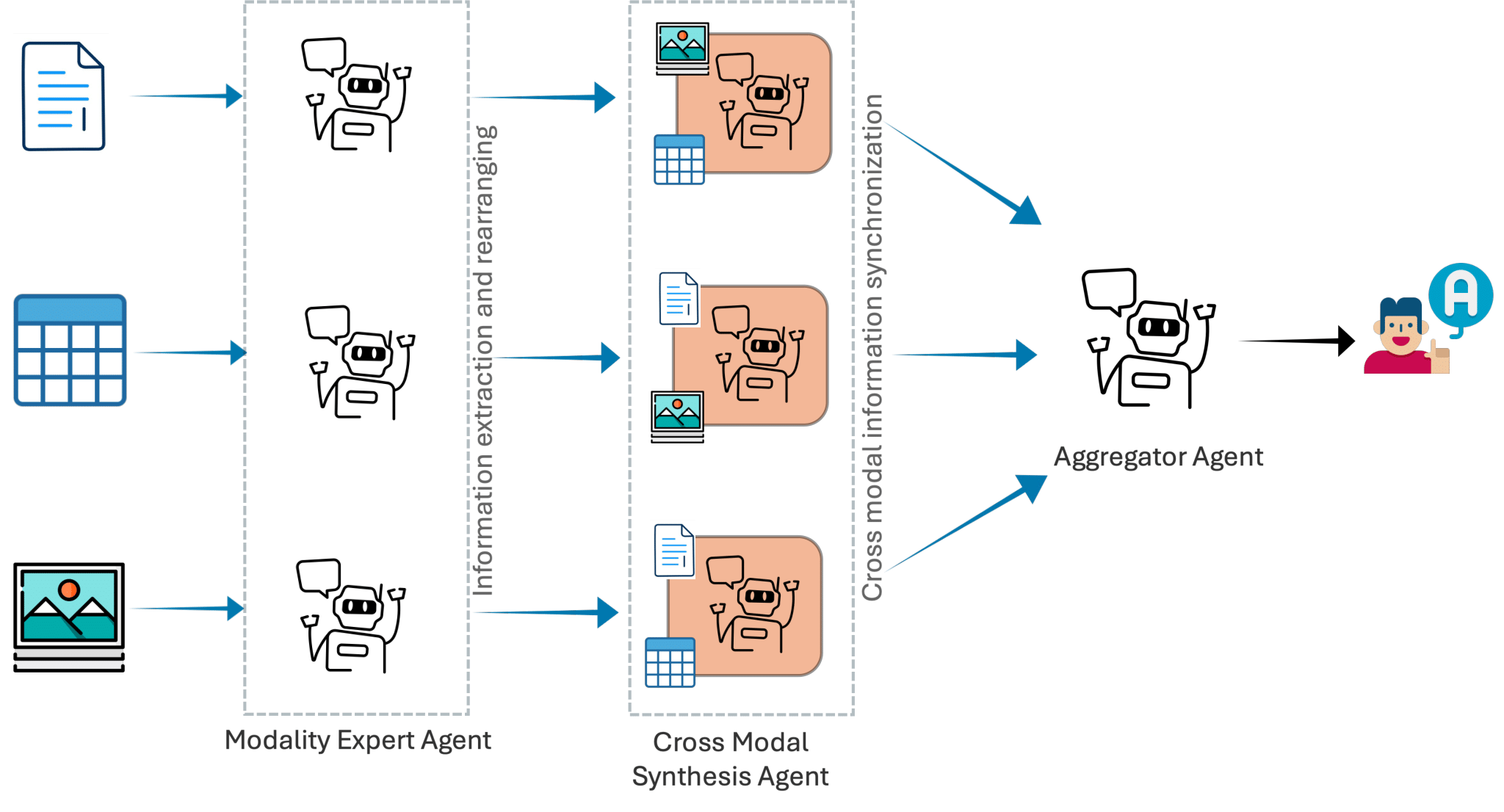
- Interpretable decomposition: MAMMQA splits retrieval, synthesis, and answer generation into explicit stages.
- Prompt-only framework: No fine-tuning is required; a shared agent template adapts across modalities.
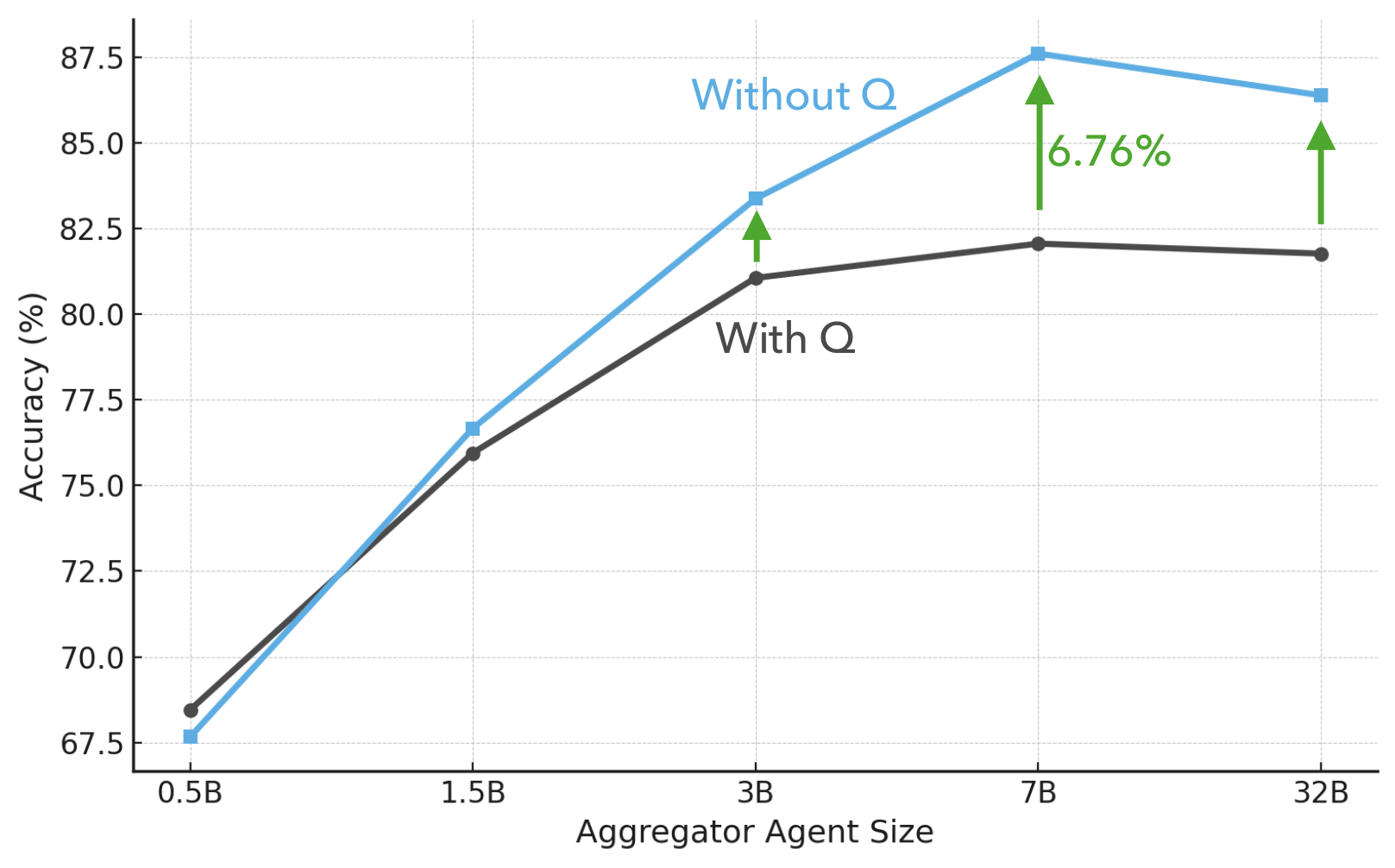
- Strong zero-shot results: The method outperforms standard prompting baselines on both ManyModalQA and MultiModalQA.
- Better calibration: The aggregator can abstain when evidence is weak, reducing overconfident unsupported answers.
MAMMQA
Rethinking Information Synthesis in Multimodal Question Answering
Multi-agent reasoning across text, tables, and images
MAMMQA replaces one-size-fits-all multimodal reasoning with a cooperative pipeline of modality experts, cross-modal synthesis, and evidence-grounded aggregation for stronger accuracy, transparency, and robustness.