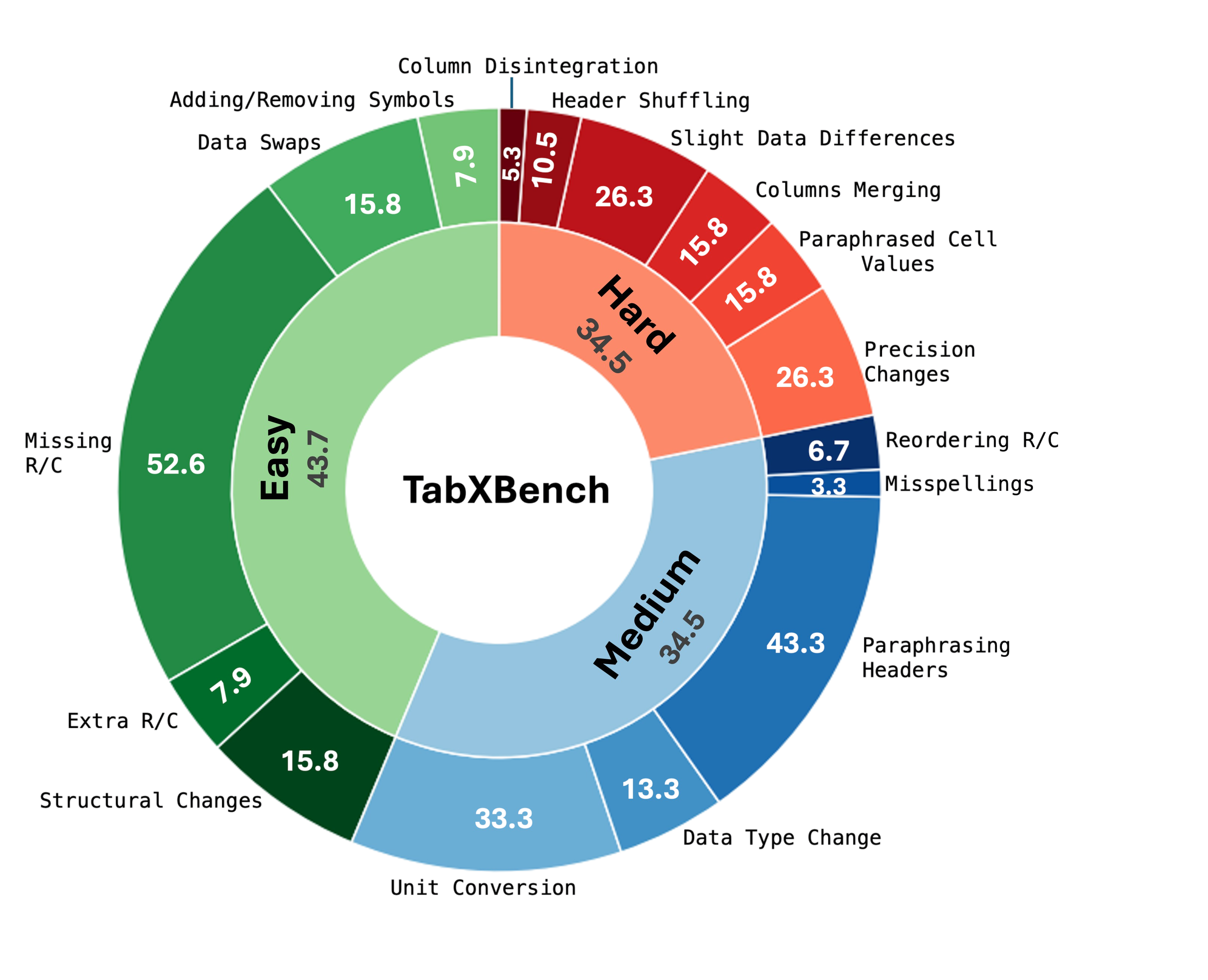
- Exhaustive rubric: combines structural descriptors with contextual quantification for comprehensive table comparison.
- Explainable evaluation: separates structural alignment from semantic comparison to reveal where systems diverge.
- Benchmark-backed analysis: TabXBench captures realistic perturbations across domains for robust metric study.
- Human alignment: results show stronger qualitative and quantitative agreement with human judgments than conventional baselines.
System Overview
From table alignment to interpretable scoring
TabXEval turns table evaluation into a structured, rubric-aware process rather than a single opaque matching score.
- TabAlign: align reference and candidate tables structurally before comparison.
- TabCompare: inspect semantic and syntactic consistency at fine granularity.
- Explainability: expose discrepancies clearly enough for qualitative analysis and diagnosis.
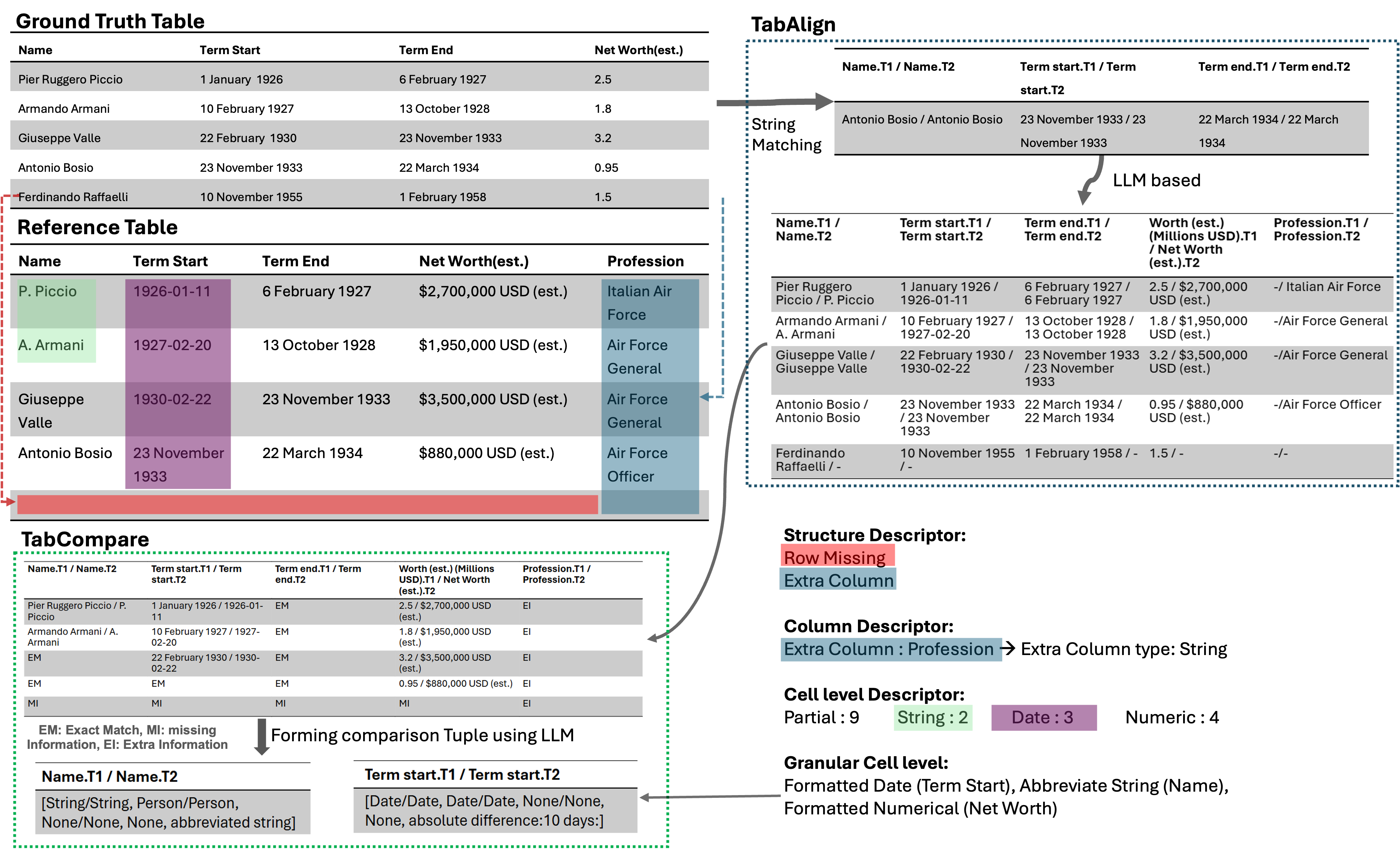
TabXEval aligns tables structurally first, then compares them semantically and syntactically for explainable evaluation.