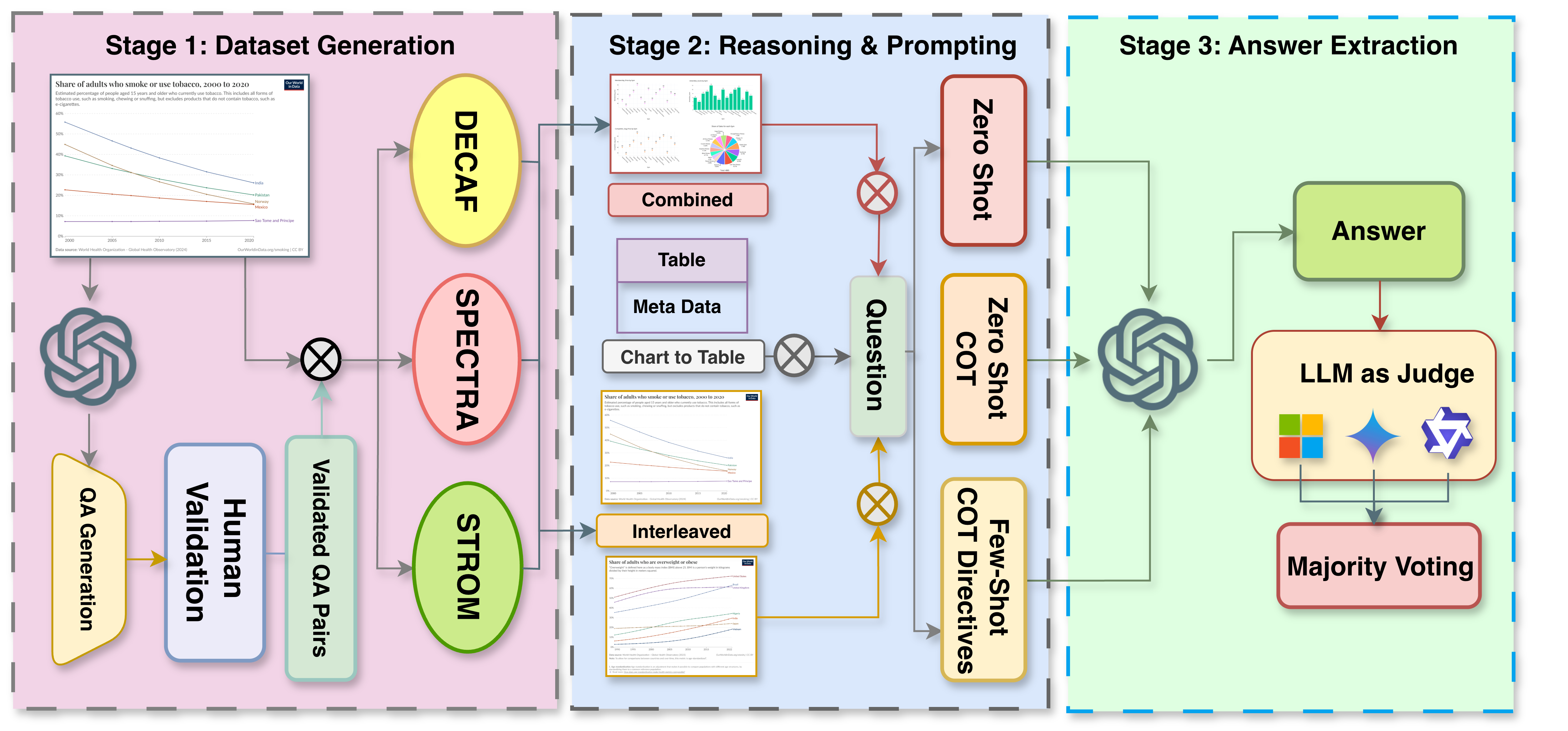
InterChart is a diagnostic benchmark for assessing how well vision-language models
reason across multiple related charts a core skill for scientific reports, finance, and public
dashboards. Unlike prior single-chart benchmarks, InterChart covers diverse question types from
entity inference and trend correlation to numerical estimation and abstract multi-step reasoning grounded
in 2–3 thematically or structurally related charts. We organize the benchmark into three tiers of increasing
difficulty: (1) factual reasoning over individual charts, (2) integrative analysis across synthetically aligned
chart sets, and (3) semantic inference over visually complex, real-world chart pairs.
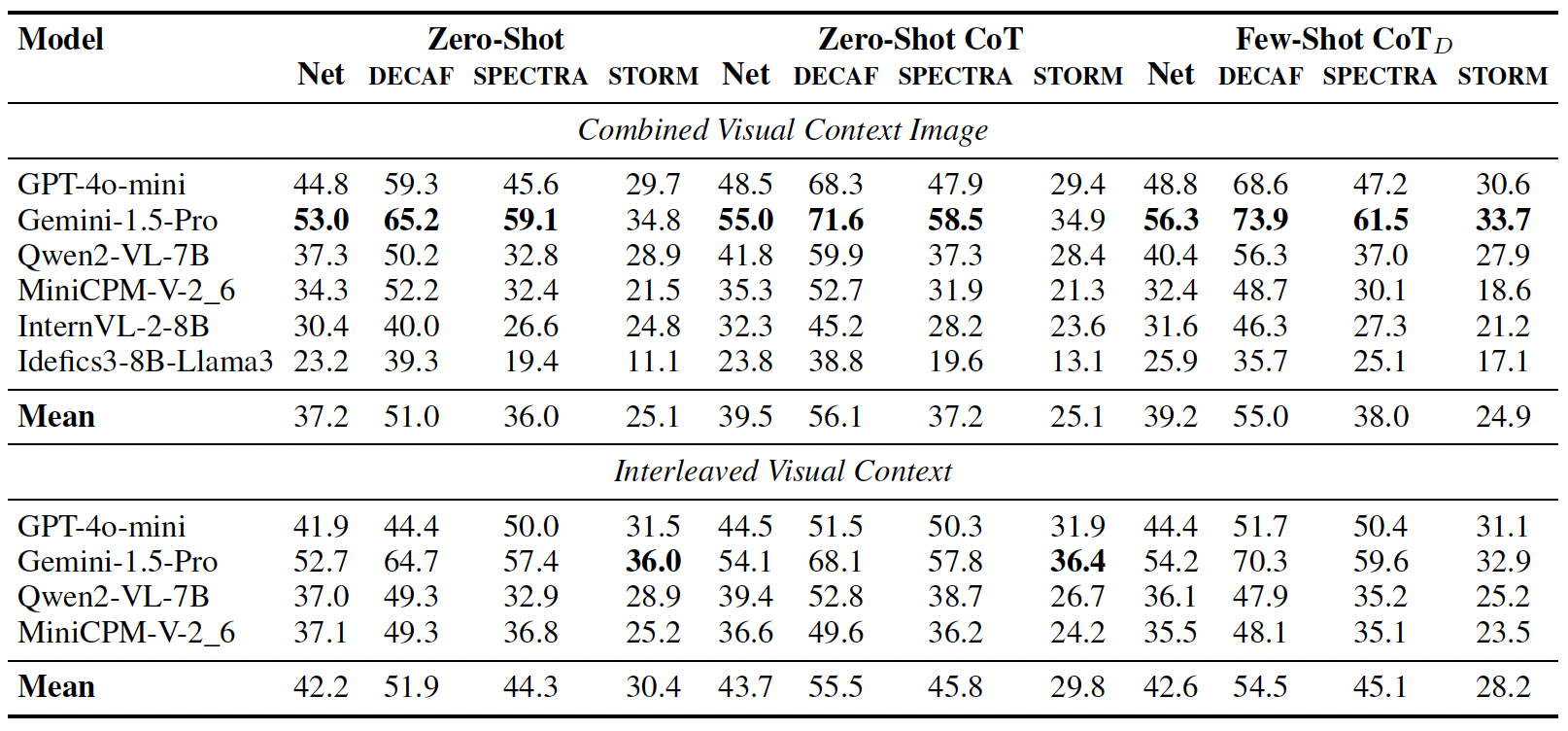
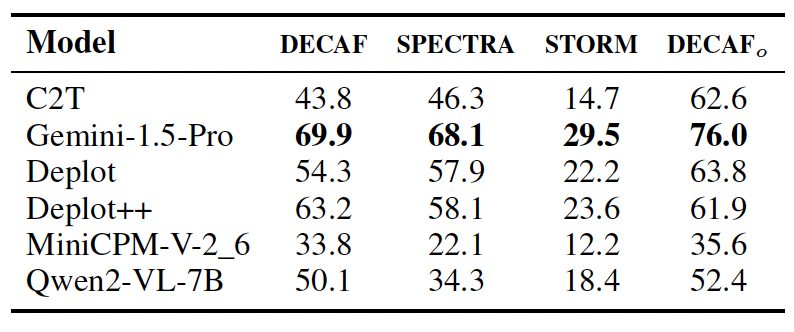
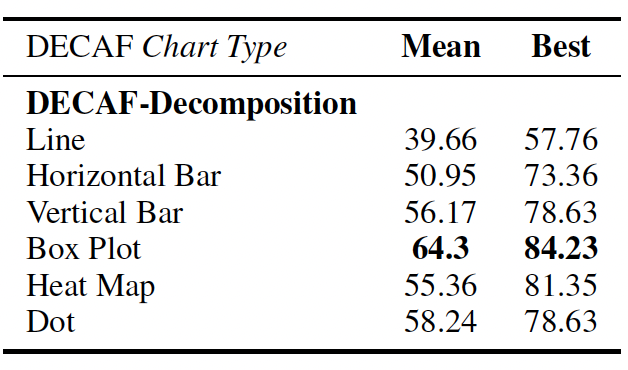
Evaluations on state-of-the-art open- and closed-source VLMs reveal consistent accuracy drops as
visual complexity rises, while chart decomposition improves performance highlighting current
limitations in cross-chart integration. Overall, InterChart provides a rigorous framework for advancing
multimodal reasoning in complex, multi-visual settings.
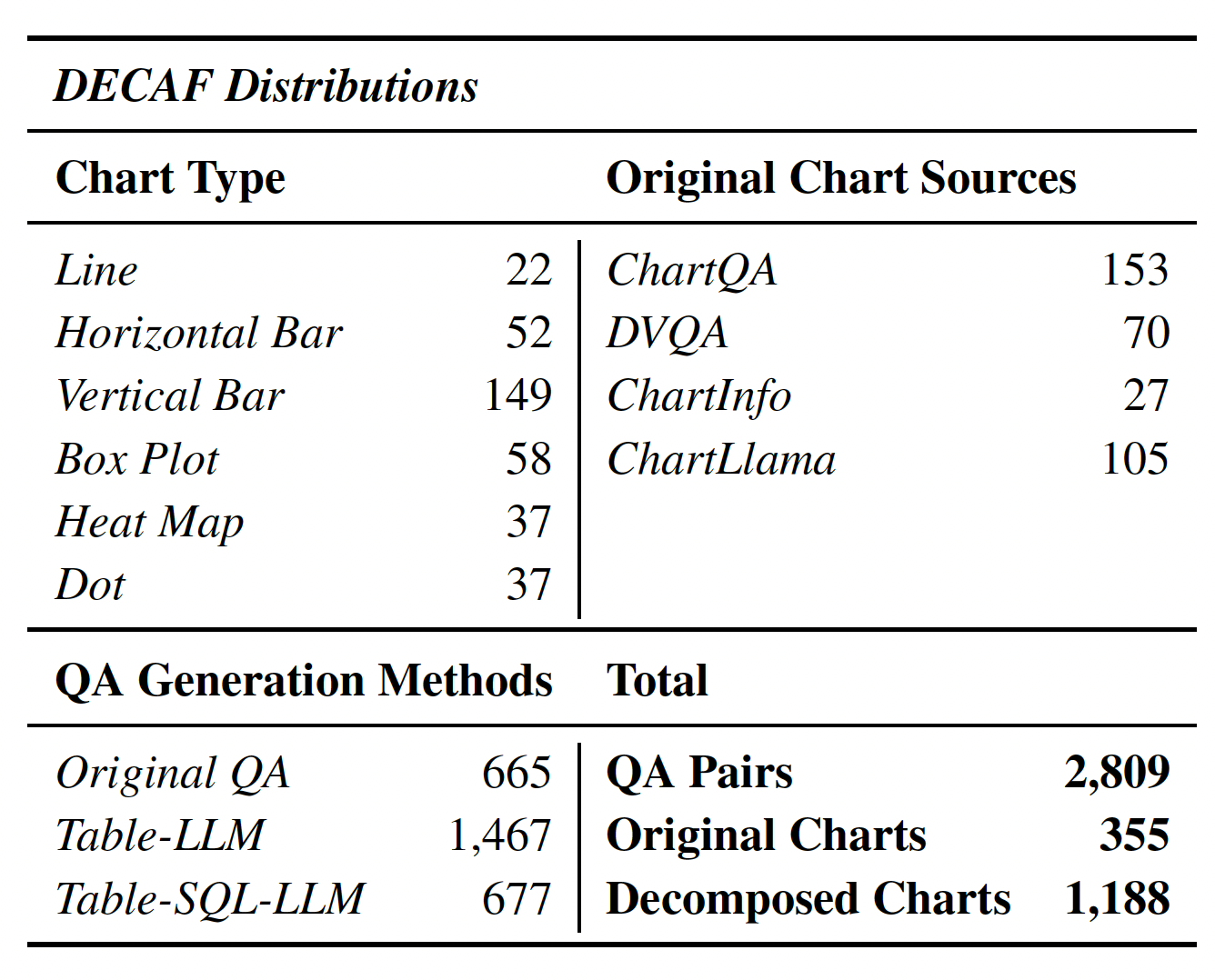
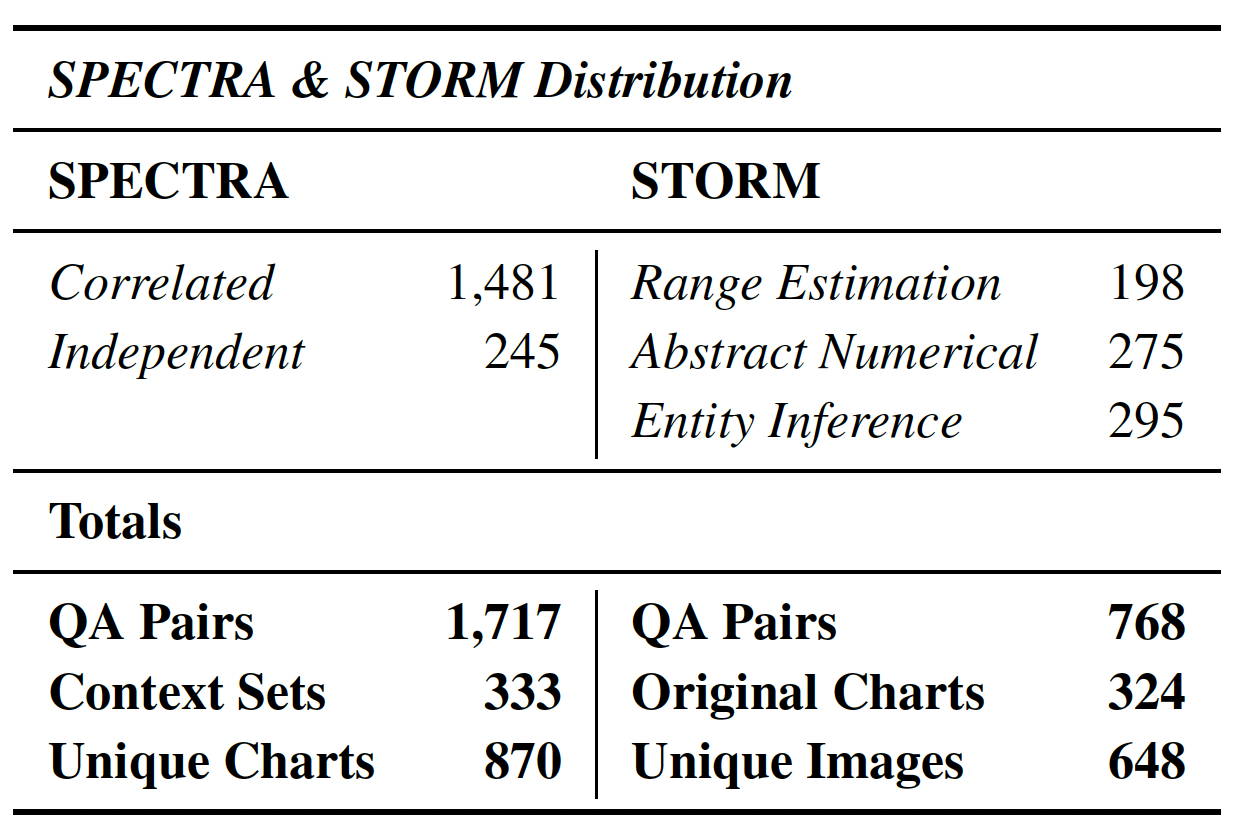
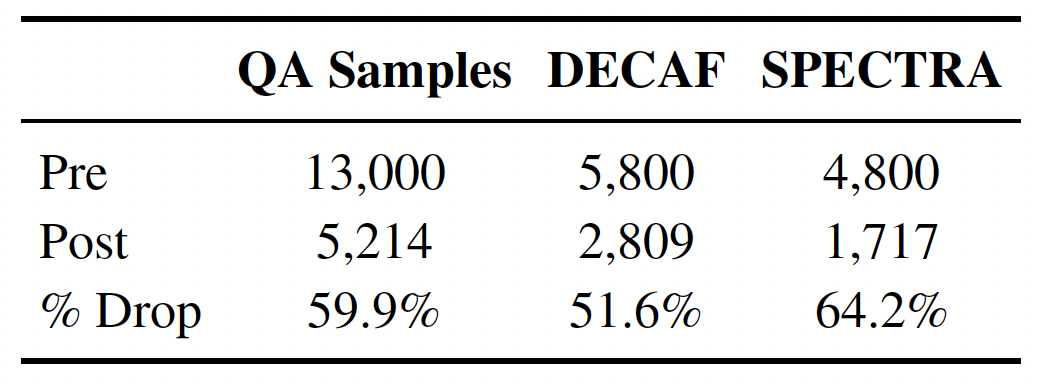
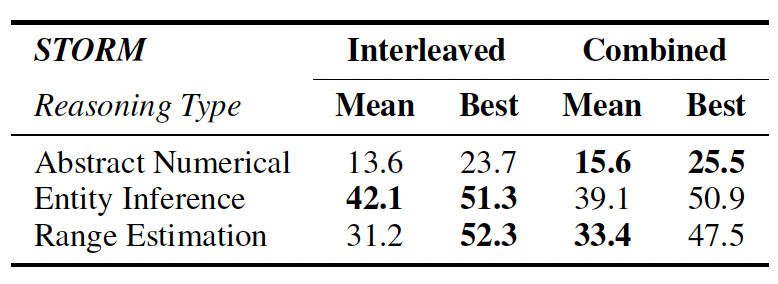
Dataset scope (high level): 5,214 validated QA pairs spanning three subsets DECAF, SPECTRA, and
STORM across 1,012 multi-chart contexts and 2,706 unique chart images.
 ,
Srija Mukhopadhyay*
,
Srija Mukhopadhyay*
 ,
Adnan Qidwai*
,
Adnan Qidwai*
 ,
Dan Roth
,
Dan Roth
 ,
Vivek Gupta
,
Vivek Gupta


 Anirudh Iyengar
Anirudh Iyengar
 Srija
Srija  Adnan Qidwai
Adnan Qidwai
 Shubhankar
Shubhankar  Dan Roth
Dan Roth
 Vivek Gupta
Vivek Gupta