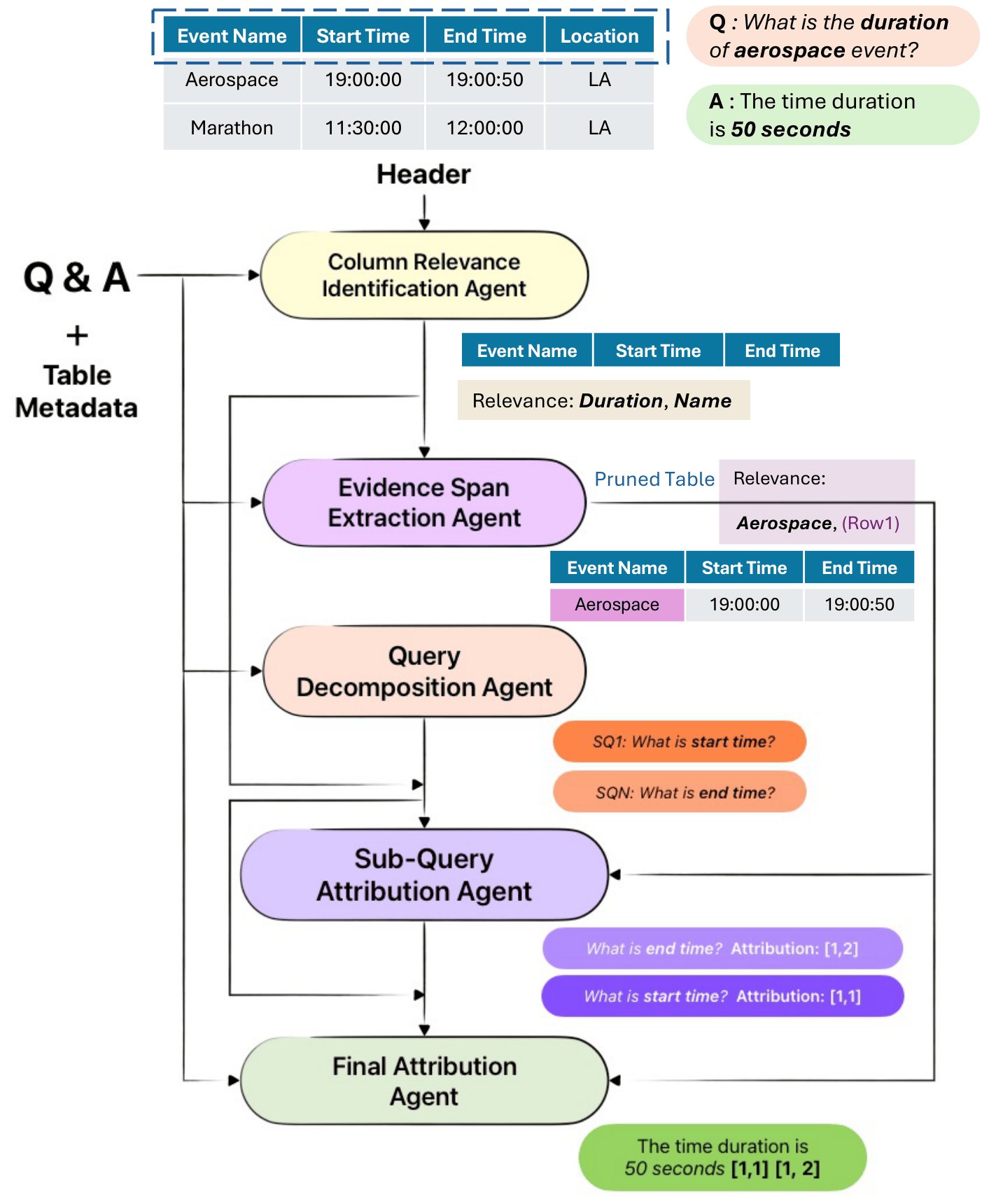
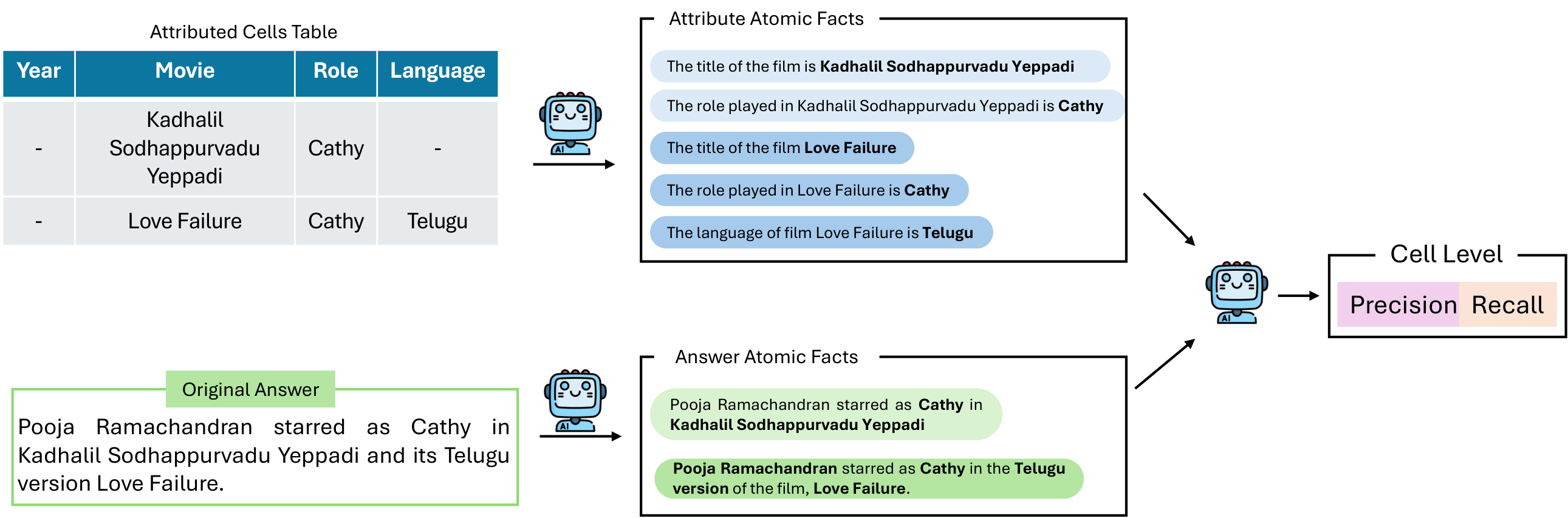
- Fine-grained attribution: TraceBack localizes the exact cells behind an answer, including intermediate evidence used in multi-step reasoning.
- Interpretable decomposition: The attribution workflow is modular, making it easier to inspect where grounding succeeds or fails.
- Benchmark-backed analysis: CITEBENCH combines human gold labels with larger silver subsets across ToTTo, FetaQA, and AITQA.
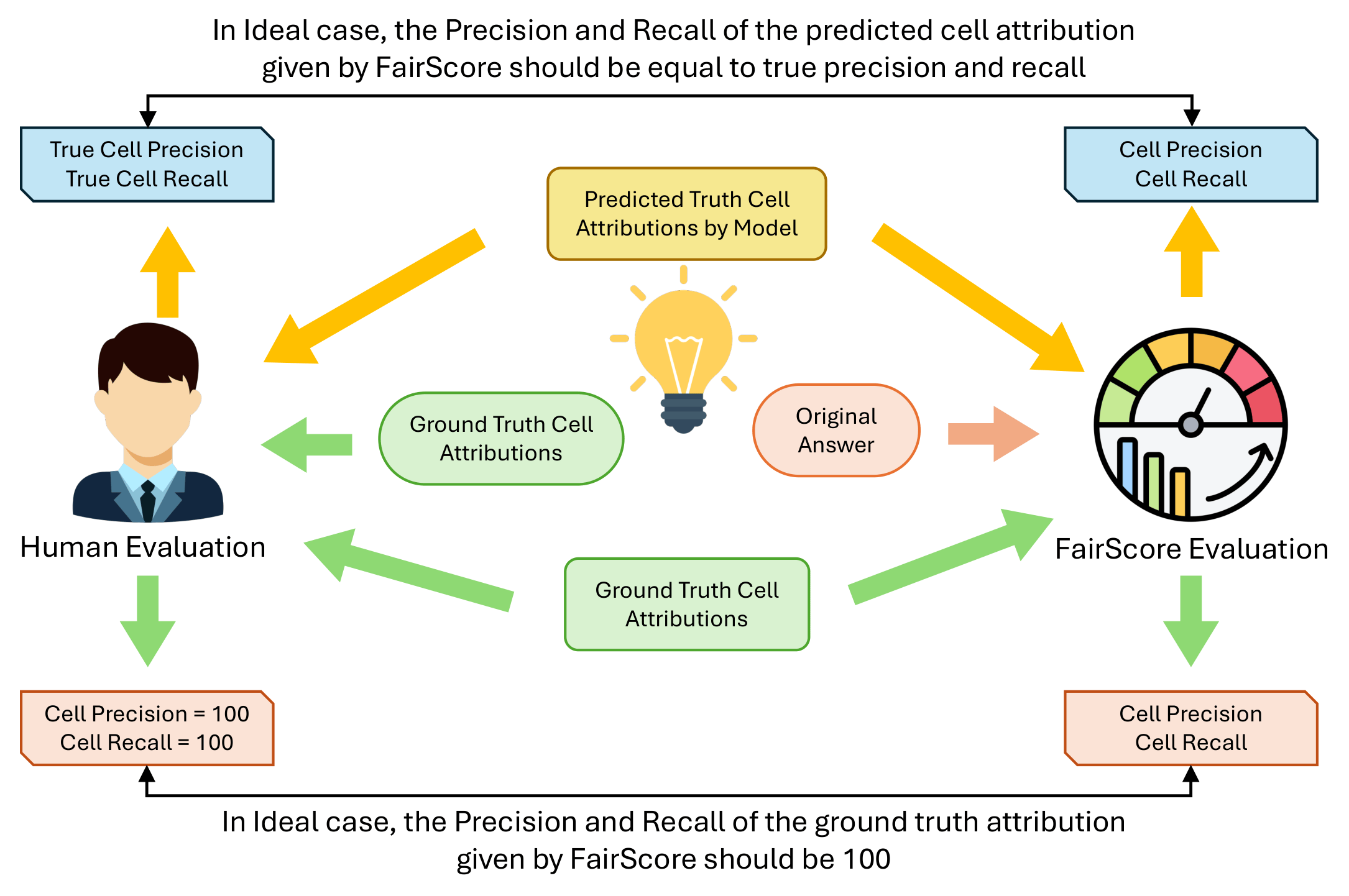
- Reference-less evaluation: FairScore compares atomic facts from predicted evidence and answers to scale analysis without new labels.
TraceBack
Multi-Agent Decomposition for Fine-Grained Table Attribution
A multi-agent attribution framework that reconstructs answer evidence step by step, introduces CITEBENCH for fine-grained analysis, and uses FairScore for scalable reference-less evaluation.