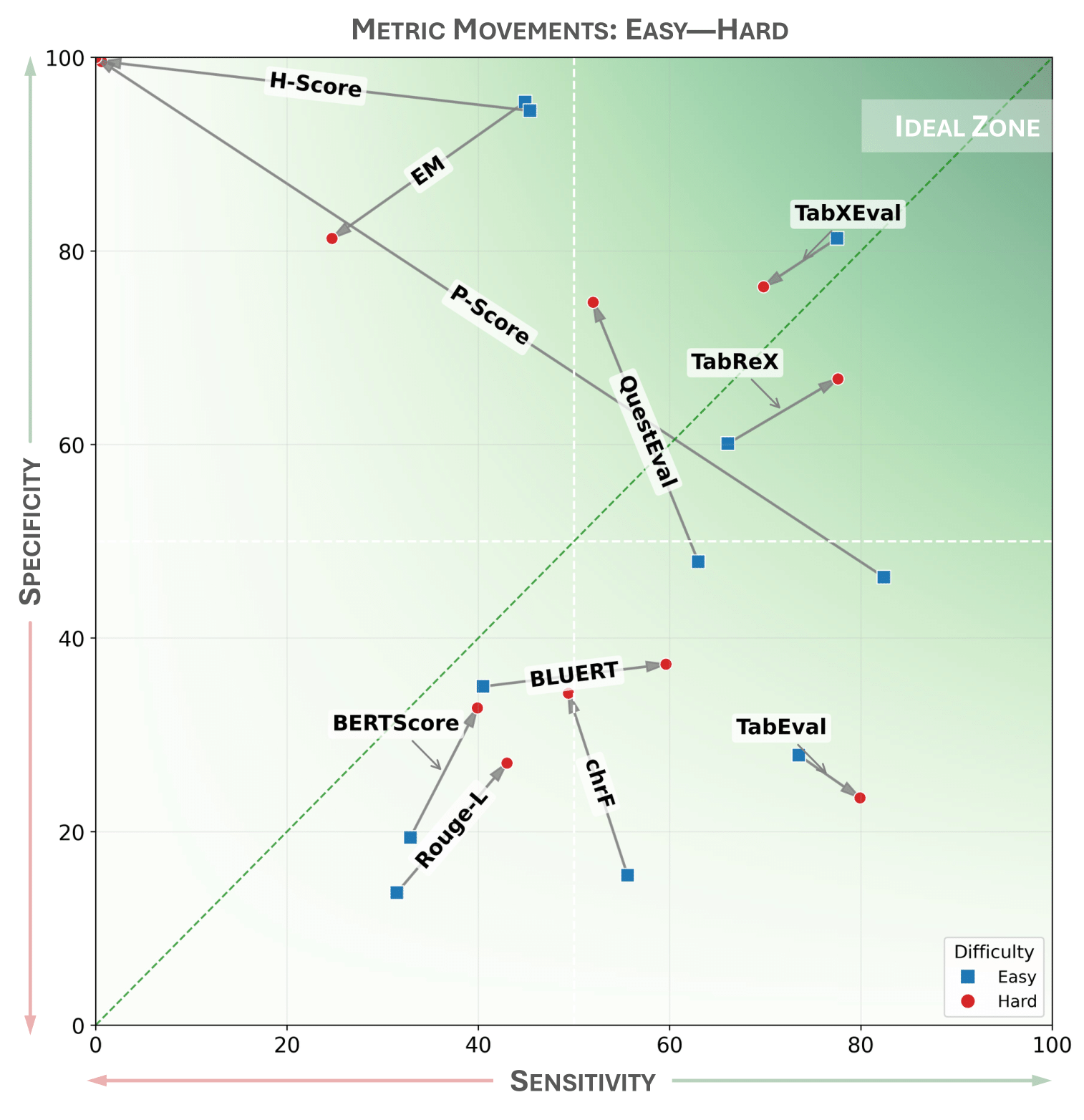
- Human alignment: TabReX reaches ρS = 74.51 and τK = 64.24 on TabReX-Bench, outperforming other referenceless baselines.
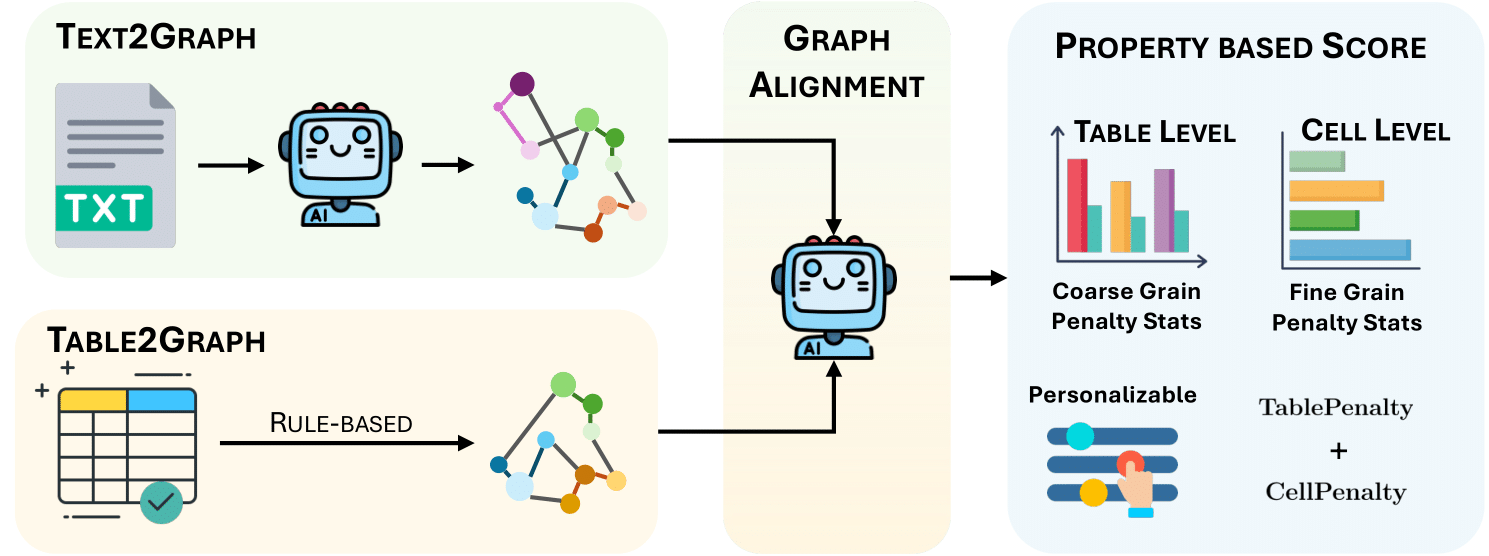
- Interpretability: The metric returns explicit cell- and table-level traces instead of a single opaque score.
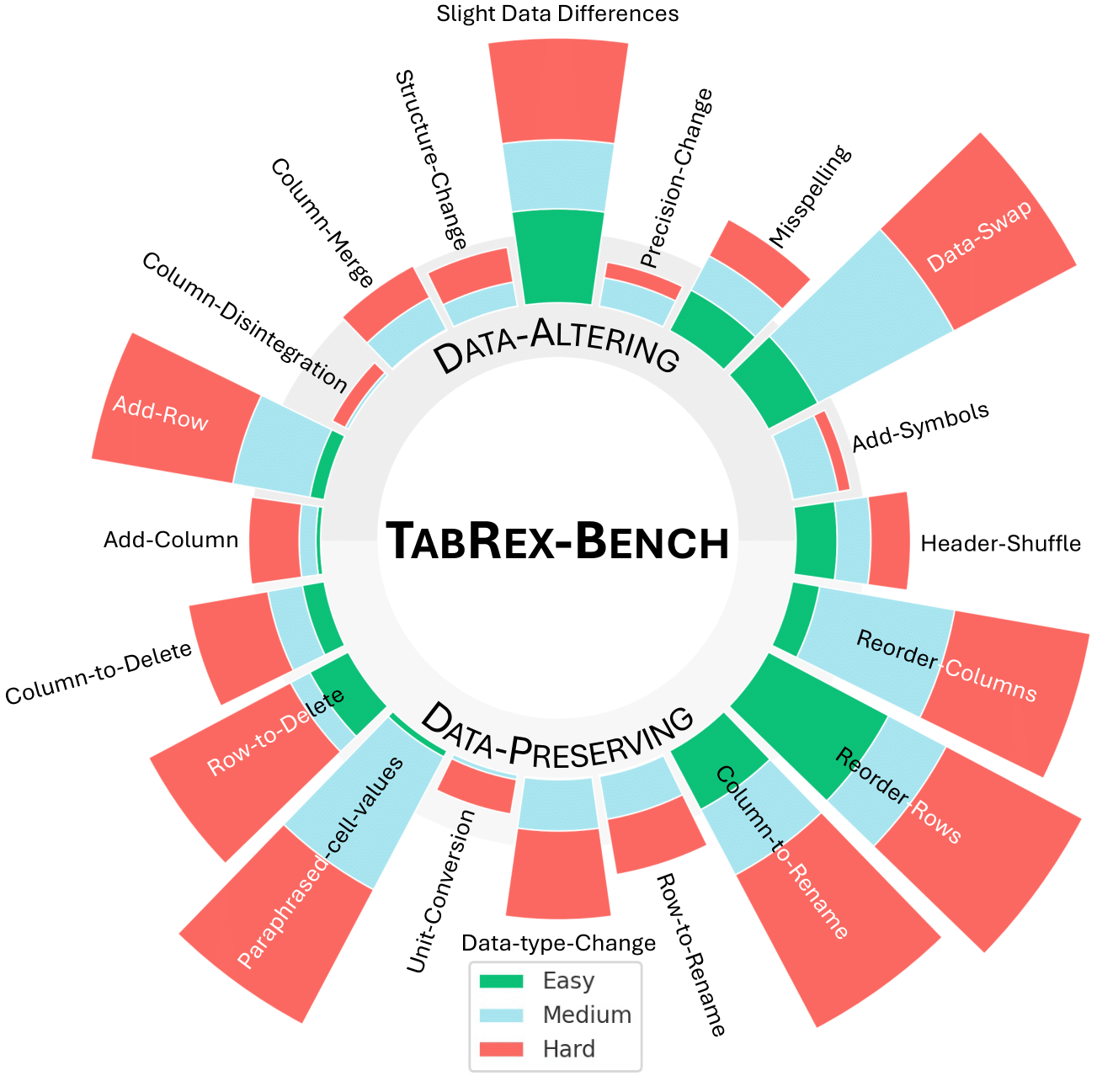
- Robustness: The benchmark probes schema edits, entity swaps, numeric errors, and harder perturbation tiers.
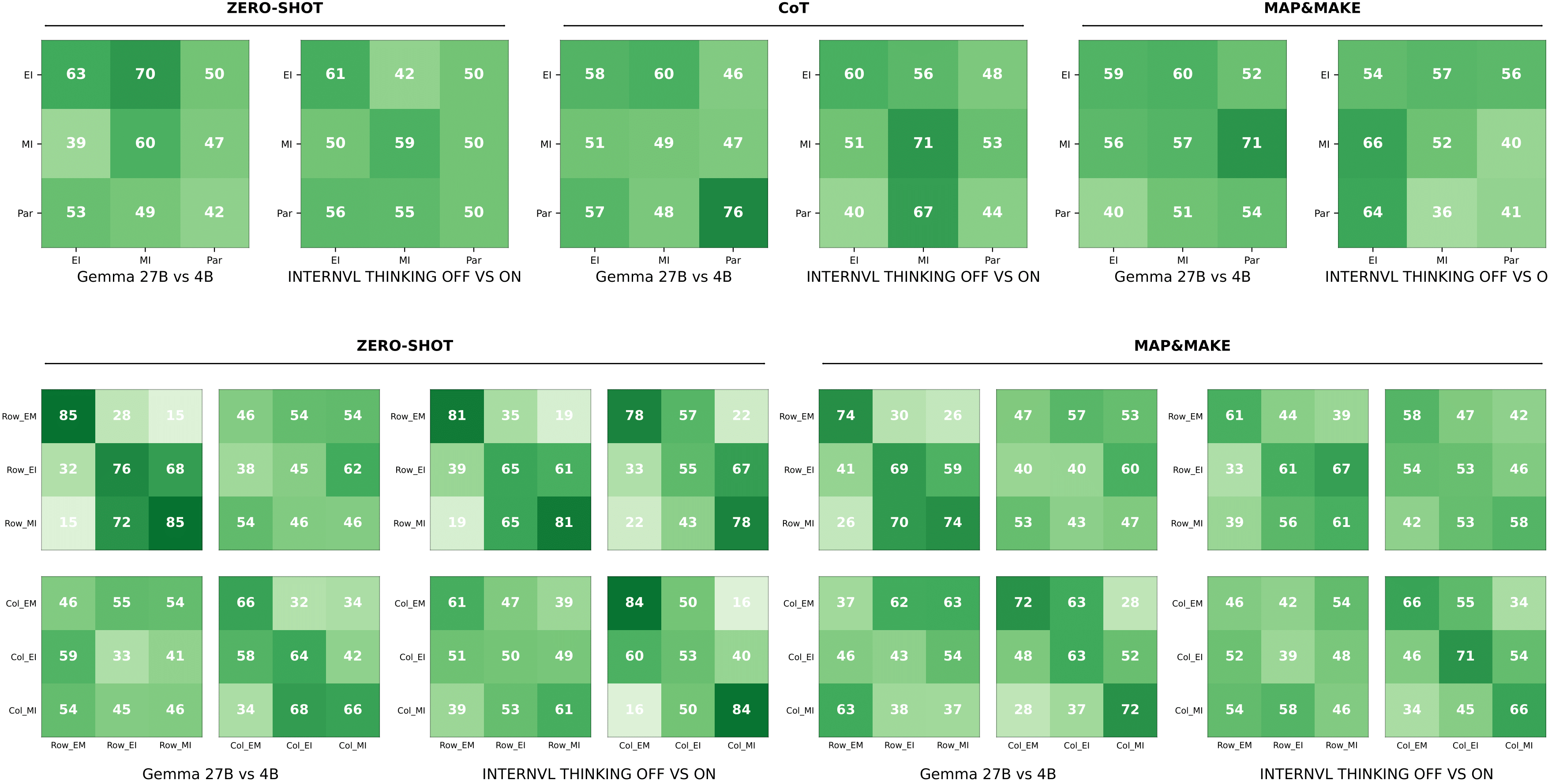
- Actionable analysis: TabReX supports model and prompt comparisons with a tunable sensitivity-specificity trade-off.
TabReX:
Tabular Referenceless eXplainable Evaluation
Accepted to ACL Mains 2026 🎉
A referenceless, graph-grounded metric for evaluating generated tables with interpretable error traces and robust human alignment.